自然场景人脸检测在美团业务中也有着广泛的应用需求,为了应对自然场景应用本身的技术挑战,同时满足业务的性能需求,美团视觉智能中心(VisionIntelligenceCenter,VIC)从底层算法模型和系统架构两个方面进行了改进,开发了高精度人脸检测模型VICFace。而且VICFace在国际知名的公开测评集WIDERFACE上达到了行业主流水平。
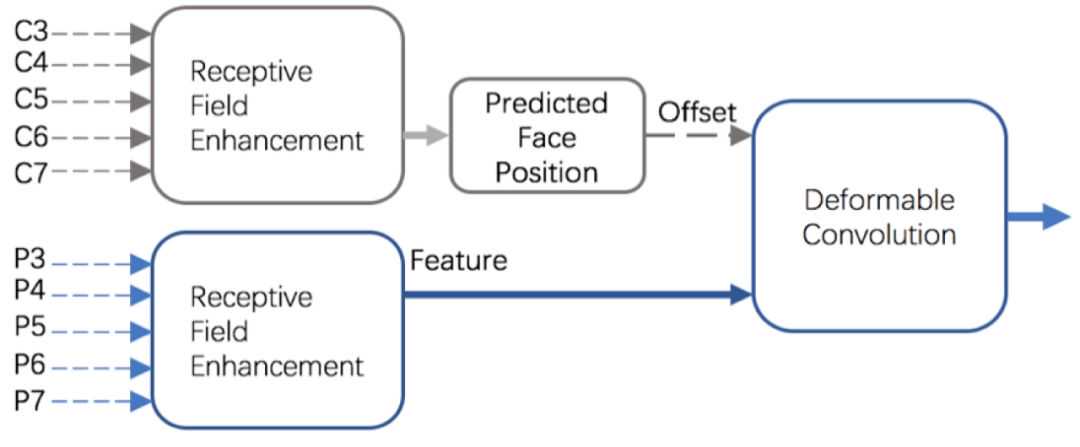
图1自然场景人脸检测样本示例
二、技术发展现状跟深度学习不同,传统方法解决自然场景人脸检测会从特征表示和分类器学习两个方面进行设计。最有代表性的工作是Viola-Jones算法[2],它利用手工设计的Haar-like特征和Adaboost算法来完成模型训练。传统方法在CPU上检测速度快,结果可解释性强,在相对可控的环境下可以达到较好的性能。但是,当训练数据规模成指数增长时,传统方法的性能提升相对有限,在一些复杂场景下,甚至无法满足应用需求。
随着计算机算力的提升和训练数据的增长,基于深度学习的方法在人脸检测任务上取得了突破性进展,在检测性能上相对于传统方法具有压倒性优势。基于深度学习的人脸检测算法从算法结构上可以大致分为三类:
1)基于级联的人脸检测算法。
2)两阶段人脸检测算法。
3)单阶段人脸检测算法。
其中,第一类基于级联的人脸检测方法(如CascadeCNN[3]、MTCNN[4])运行速度较快、检测性能适中,适用于算力有限、背景简单且人脸数量较少的场景。第二类两阶段人脸检测方法一般基于Faster-RCNN[6]框架,在第一阶段生成候选区域,然后在第二阶段对候选区域进行分类和回归,其检测准确率较高,缺点是检测速度较慢,代表方法有FaceR-CNN[9]、ScaleFace[10]、FDNet[11]。最后一类单阶段的人脸检测方法主要基于Anchor的分类和回归,通常会在经典框架(如SSD[12]、RetinaNet[13])的基础上进行优化,其检测速度较两阶段法快,检测性能较级联法优,是一种检测性能和速度平衡的算法,也是当前人脸检测算法优化的主流方向。
三、优化思路和业务应用在自然场景应用中,为了同时满足精度需求以及达到实用的目标,美团视觉智能中心(VisionIntelligenceCenter,VIC)采用了主流的Anchor-Based单阶段人脸检测方案,同时在数据增强和采样策略、模型结构设计和损失函数等三方面分别进行了优化,开发了高精度人脸检测模型VICFace。以下是相关技术细节的介绍。
1.数据增强和采样策略单阶段通用目标检测算法对数据增强方式比较敏感,如经典的SSD算法在VOC2007[50]数据集上通过数据增强性能指标mAP提升6.7。经典单阶段人脸检测算法S3FD[17]也设计了样本增强策略,使用了图片随机裁切,图片固定宽高比缩放,图像色彩扰动和水平翻转等。
百度在ECCV2018发表的PyramidBox[18]提出了Data-Anchor采样方法,将图像中一个随机选择的人脸进行尺度变换变成一个更小Anchor附近尺寸的人脸,同时训练图像的尺寸也进行同步变换。这样做的好处是通过将较大的人脸生成较小的人脸,提高了小尺度上样本的多样性,在WIDERFACE[1]数据集Easy、Medium、Hard集合上分别提升0.4(94.3-94.7),0.4(93.3-93.7),0.6(86.1-86.7)。ISRN[19]将SSD的样本增强方式和Data-Anchor采样方法结合,模型检测性能进一步提高。
而VICFace在ISRN样本增强方式的基础上对语义模糊的超小人脸做了过滤,而mixup[22]在图像分类和目标检测中已经被验证有效,现在用于人脸检测,有效地防止了模型过拟合问题。考虑到业务数据中人脸存在多姿态、遮挡和模糊的样本,且这些样本在训练集中占比小,检测难度大,因此在模型训练时动态的给这些难样本赋予更高的权重从而提升这些样本的召回率。
2.模型结构设计人脸检测模型结构设计主要包括检测框架、主干网络、预测模块、Anchor设置与正负样本划分等四个部分,是单阶段人脸检测方法优化的核心。
检测框架
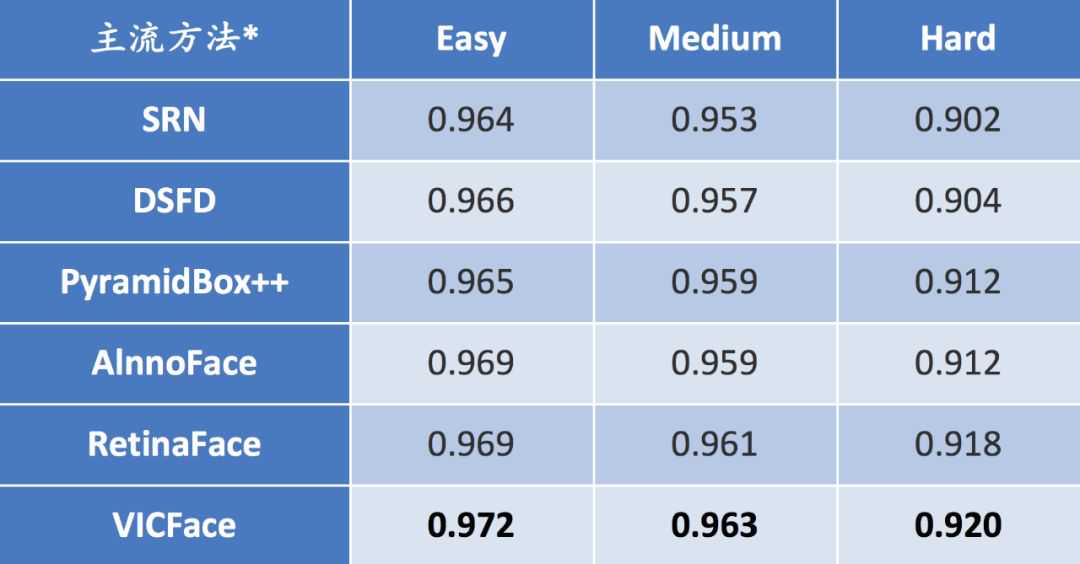
近年来单阶段人脸检测框架取得了重要的发展,代表性的结构有S3FD[17]中使用的SSD,SFDet[25]中使用的RetinaNet,SRN[23]中使用的两步结构(后简称SRN)以及DSFD[24]中使用的双重结构(后简称DSFD),如下图2所示。其中,SRN是一种单阶段两步人脸检测方法,利用第一步的检测结果,在小尺度人脸上过滤易分类的负样本,改善正负样本数量的均衡性,针对大尺度的人脸采用迭代求精的方式进行人脸定位,改善大尺度人脸的定位精度,提升了人脸检测的准确率。在WIDERFACE上测评SRN取得了最好的检测效果(按标准协议用AP平均精度来衡量),如表1所示。
S3FD:
SFDet:
SRN:
DSFD:
图2四种检测结构
表1Backbone为ResNet50时,四种检测结构在WIDERFACE上的评估结果
VICFace继承了当前性能最好的SRN检测结构,同时为了更好的融合自底向上和自顶向下的特征,为不同特征不同通道赋予不同的权重,以P4为例,其计算式为:
其中WC4向量的元素个数与Conv(C4)特征的通道数相等,WP4与Upsample(P5)的通道数相等,WC4与WP4是可学习的,其元素值均大于0,且WC4与WP4对应元素之和为1,结构如图3所示。
图3视觉智能中心VICFace网络整体结构图
主干网络
单阶段人脸检测模型的主干网络通常使用分类任务中的经典结构(如VGG[26]、ResNet[27]等)。其中,主干网络在ImageNet数据集上分类任务表现越好,其在WIDERFACE上的人脸检测性能也越高,如表2所示。为了保证检测网络得到更高的召回,在性能测评时VICFace主干网络使用了在ImageNet上性能较优的ResNet152网络(其在ImageNet上Top1分类准确率为80.26),并且在实现时将Kernel为7x7,Stride为2的卷积模块调整为为3个3x3的卷积模块,其中第一个模块的Stride为2,其它的为1;将Kernel为1x1,Stride为2的下采样模块替换为Stride为2的Avgpool模块。
表2不同主干网络在ImageNet的性能对比和其在RetinaNet框架下的检测精度
预测模块
利用上下文信息可以进一步提高模型的检测性能。SSH[36]是将上下文信息用于单阶段人脸检测模型的早期方案,PyramidBox、SRN、DSFD等也设计了不同上下文模块。如图4所示,SRN上下文模块使用1xk,kx1的卷积层提供多种矩形感受野,多种不同形状的感受野助于检测极端姿势的人脸;DSFD使用多个带孔洞的卷积,极大的提升了感受野的范围。
图4不同网络结构中的ContextModule
在VICFace中,将带孔洞的卷积模块和1xk,kx1的卷积模块联合作为ContextModule,既提升了感受野的范围也有助于检测极端姿势的人脸,同时使用Maxout模块提升召回率,降低误检率。它还利用Cn层特征预测的人脸位置,校准Pn层特征对应的区域,如图5所示。Cn层预测的人脸位置相对特征位置的偏移作为可变卷积的Offset输入,Pn层特征作为可变卷积的Data输入,经过可变卷积后特征对应的区域与人脸区域对应更好,相对更具有表示能力,可以提升人脸检测模型的性能。
图5自研检测模型结构中的预测模块
Anchor设置与正负样本划分
在自研方案中,在C3、P3层,Anchor的大小为2S和4S,其它层Anchor大小为4S(S代表对应层的Stride),这样的Anchor设置方式在保证人脸召回率的同时,减少了负样本的数量,在一定程度上缓解了正负样本不均衡现象。根据人脸样本宽高比的统计信息,将Anchor的宽高比设置为0.8,同时将Cn层IoU大于0.7的样本划分为正样本,小于0.3的划分为负样本,Pn层IoU大于0.5的样本划分为正样本,小于0.4的划分为负样本。
3.损失函数人脸检测的优化目标不仅需要区分正负样本(是否是人脸),还需要定位出人脸位置和尺寸。S3FD中区分正负样本使用交叉熵损失函数,定位人脸位置和尺寸使用SmoothL1Loss,同时使用困难负样本挖掘解决正负样本数量不均衡的问题。另一种缓解正负样本不均衡带来的性能损失更直接的方式是Lin等人提出FocalLoss[13]。UnitBox[41]提出IoULoss可以缓解不同尺度人脸的定位损失差异大导致的性能损失。AlnnoFace[40]同时使用FocalLoss和IoULoss提升了人脸检测模型的性能。引入其它相关辅助任务也可以提升人脸检测算法的性能,RetinaFace[42]引入关键点定位任务,提升人脸检测算法的定位精度;DFS[43]引入人脸分割任务,提升了特征的表示能力。
综合前述方法的优点,VICFace充分利用人脸检测及相关任务的互补信息,使用多任务方式训练人脸检测模型。在人脸分类中使用FocalLoss来缓解样本不均衡问题,同时使用人脸关键点定位和人脸分割来辅助分类目标的训练,从而提升整体的分类准确率。在人脸定位中使用CompleteIoULoss[47],以目标与预测框的交并比作为损失函数,缓解不同尺度人脸损失的差异较大的问题,同时兼顾目标和预测框的中心点距离和宽高比差异,从而可以达到更好整体检测性能。
4.优化结果和业务应用在集群平台的支持下,美团视觉智能中心的自然场景人脸检测基础模型VICFace与现有主流方案进行了性能对比,在国际公开人脸检测测评集WIDERFACE的三个验证集Easy、Medium、Hard中均达到领先水平(AP为平均精度,数值越高越好),如图6和表3所示。
图6VICFace以及当前主流人脸检测方法在WIDERFACE上的测评结果
表3VICFace以及当前主流人脸检测方法在WIDERFACE上的测评结果
注:SRN是中科院在AAAI2019提出的新方法,DSFD是腾讯优图在CVPR2019提出的新方法,PyramidBox++是百度在2019年提出的新方法,AInnoFace是创新奇智在2019提出的新方法,RetinaFace是ICCV2019WiderChallenge亚军。
在业务应用中,自然场景人脸检测服务目前已接入美团多个业务线,满足了业务在UGC图像智能过滤和广告POI图像展示等应用的性能需求,前者保护用户隐私,预防侵犯用户肖像权,后者可以有效的预防图像中人脸局部被裁切的现象,从而提升了用户体验。此外,VICFace还为其它人脸智能分析应用提供了核心基础模型,如自动检测后厨工作人员的着装合规性(是否穿戴帽子和口罩),为食品安全增加了一道保障。
参考文献1.YangS,LuoP,LoyCC,:Afacedetectionbenchmark[C]//Proc:5525-5533.
2.ViolaP,[J].Internationaljournalofcomputervision,2004,57(2):137-154.
3.LiH,LinZ,ShenX,[C]//Proc:5325-5334.
4.ZhangK,ZhangZ,LiZ,alnetworks[J].IEEESignalProcessingLetters,2016,23(10):1499-1503.
5.HaoZ,LiuY,QinH,[C]//Proc:6186-6195.
6.RenS,HeK,GirshickR,:Towardsreal-timeobjectdetectionwithregionproposalnetworks[C]//:91-99.
7.LinTY,DollárP,GirshickR,[C].Proc:2117-2125.
8.JiangH,[C]//201712thIEEEInternationalConferenceonAutomaticFaceGestureRecognition(FG2017).IEEE,2017:650-657.
9.WangH,LiZhif,:1706.01061,2017.
10.YangS,XiongY,LoyCC,[J].arXivpreprintarXiv:1706.02863,2017.
11.ZhangC,XuX,[J].arXivpreprintarXiv:1802.02142,2018.
12.LiuW,AnguelovD,ErhanD,:Singleshotmultiboxdetector[C]//,Cham,2016:21-37.
13.LinTY,GoyalP,GirshickR,[C]//:2980-2988.
14.HuangL,YangY,DengY,:Unifyinglandmarklocalizationwithtoobjectdetection[J].arXivpreprintarXiv:1509.04874,2015.
15.LiuW,LiaoS,RenW,:ANewPerspectiveforPedestrianDetection[C]//Proc:5187-5196.
16.ZhangZ,HeT,ZhangH,[J].arXivpreprintarXiv:1902.04103,2019.
17.ZhangS,ZhuX,LeiZ,:Singleshotscale-invariantfacedetector[C]//:192-201.
18.TangX,DuDK,HeZ,:Acontext-assistedsingleshotfacedetector[C]//ProceedingsoftheEuropeanConferenceonComputerVision(ECCV).2018:797-813.
19.ZhangS,ZhuR,WangX,[J].arXivpreprintarXiv:1901.06651,2019.
20.LiZ,TangX,HanJ,++:HighPerformanceDetectorforFindingTinyFace[J].arXivpreprintarXiv:1904.00386,2019.
21.ZhangS,ZhuX,LeiZ,:ACPUreal-timefacedetectorwithhighaccuracy[C]//2017IEEEInternationalJointConferenceonBiometrics(IJCB).IEEE,2017:1-9.
22.ZhangH,CisseM,DauphinYN,:Beyondempiricalriskminimization[J].arXivpreprintarXiv:1710.09412,2017.
23.ChiC,ZhangS,XingJ,[C]//,33:8231-8238.
24.LiJ,WangY,WangC,:dualshotfacedetector[C]//Proc:5060-5069.
25.ZhangS,WenL,ShiH,[J].InternationalJournalofComputerVision,2019,127(6-7):537-559.
26.SimonyanK,[J].arXivpreprintarXiv:1409.1556,2014.
27.HeK,ZhangX,RenS,[C]//Proc:770-778.
28.XieS,GirshickR,DollárP,[C]//Proc:1492-1500.
29.IandolaF,MoskewiczM,KarayevS,:Implementingefficientconvnetdescriptorpyramids[J].arXivpreprintarXiv:1404.1869,2014.
30.HowardAG,ZhuM,ChenB,:Efficientconvolutionalneuralnetworksformobilevisionapplications[J].arXivpreprintarXiv:1704.04861,2017.
31.SandlerM,HowardA,ZhuM,:Invertedresidualsandlinearbottlenecks[C]//Proc:4510-4520.
32.BazarevskyV,KartynnikY,VakunovA,:Sub-millisecondNeuralFaceDetectiononMobileGPUs[J].arXivpreprintarXiv:1907.05047,2019.
33.HeY,XuD,WuL,:ALightandFastFaceDetectorforEdgeDevices[J].arXivpreprintarXiv:1904.10633,2019.
34.ZhuR,ZhangS,WangX,:Exploringtotrainsingle-shotobjectdetectorsfromscratch[J].arXivpreprintarXiv:1810.08425,2018,2.
35.LinTY,MaireM,BelongieS,:Commonobjectsincontext[C]//,Cham,2014:740-755.
36.NajibiM,SamangoueiP,ChellappaR,:Singlestageheadlessfacedetector[C]//:4875-4884.
37.,,,:1912.00596,2019.
38.GoodfellowIJ,Warde-FarleyD,MirzaM,[J].arXivpreprintarXiv:1302.4389,2013.
39.ZhuC,TaoR,LuuK,'sPerspective[C]//Proc:5127-5136.
40.,,,,,:1905.01585,2019.
41.YuJ,JiangY,WangZ,:Anadvancedobjectdetectionnetwork[C]//,2016:516-520.
42.DengJ,GuoJ,ZhouY,:Single-stageDenseFaceLocalisationintheWild[J].arXivpreprintarXiv:1905.00641,2019.
43.TianW,WangZ,ShenH,ntationsupervision[J].arXivpreprintarXiv:1811.08557,2018.
44.,,:1901.02350,2019.
45.,,,::1909.04376,2019.
46.WangJ,YuanY,LiB,:Anefficientnetworkforfacedetectioninlargescalevariations[J].arXivpreprintarXiv:1804.06559,2018.
47.ZhengZ,WangP,LiuW,:FasterandBetterLearningforBoundingBoxRegression[J].arXivpreprintarXiv:1911.08287,2019.
48.BayH,TuytelaarsT,:Speededuprobustfeatures[C]//,Berlin,Heidelberg,2006:404-417.
49.YangB,YanJ,LeiZ,[C]//,2014:1-8.
50.EveringhamM,VanGoolL,WilliamsCKI,(VOC2007)results[J].2007.
51.RedmonJ,:Anincrementalimprovement[J].arXivpreprintarXiv:1804.02767,2018.
作者简介振华、欢欢、晓林,皆为美团视觉智能中心工程师。
招聘信息

-
 2025-04-23
2025-04-23 -
 2024-11-09
2024-11-09 -
 2025-05-09
2025-05-09 -

探馆成都大运会丨打卡凤凰山体育公园冰篮球馆——3小时实现“冰篮转换” 科技大运看这里
2026-02-01
-
用手机实现智能照明 两江新区企业恒亦明科技国内首创ZPLC技术
2025-12-13 -
AIC 2024中国国际房车展览会新闻发布会在沪成功举办
2025-06-05 -
三相变压器组的优缺点
2025-07-02 -
宜宾市翠屏区人民法院关于为科技法庭改造等6个项目选择第三方评审机构的比选公告
2026-02-01